I am actively seeking opportunities in both academia (postdoctoral and research fellow positions) and industry (R&D roles). Interested collaborators are welcome to connect!
2025.10: Our conference paper in ACM-MM 2025 received the Best Paper Award in the MCHM workshop
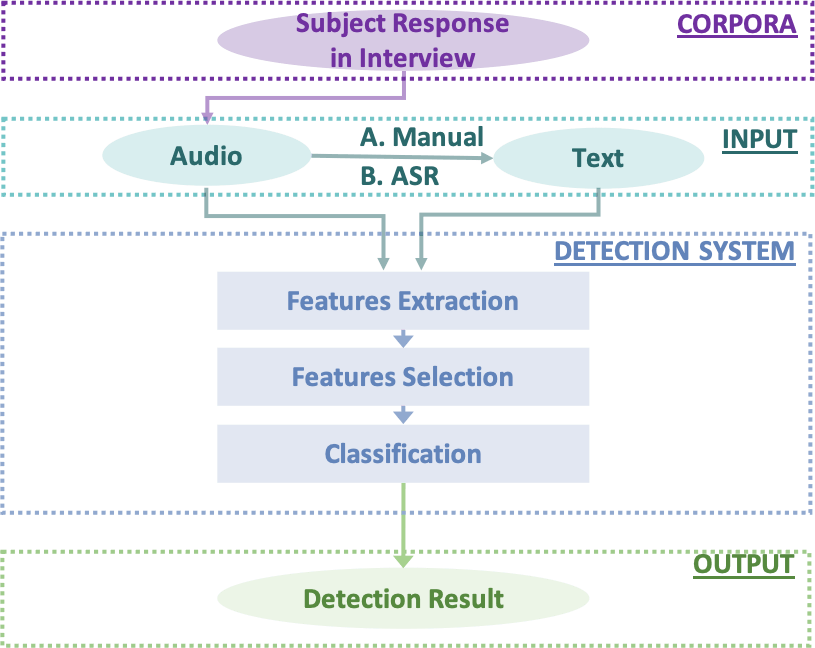
Early detection of neurocognitive disorders (NCDs) is crucial for timely intervention and disease management. Given that language impairments manifest early in NCD progression, visual-stimulated narrative (VSN)-based analysis offers a promising avenue for NCD detection. Current VSN-based NCD detection methods primarily focus on linguistic microstructures (e.g., lexical diversity) that are closely tied to bottom-up, stimulus-driven cognitive processes. While these features illuminate basic language abilities, the higher-order linguistic macrostructures (e.g., topic development) that may reflect top-down, concept-driven cognitive abilities remain underexplored. These macrostructural patterns are crucial for NCD detection, yet challenging to quantify due to their abstract and complex nature. To bridge this gap, we propose two novel macrostructural approaches: (1) a Dynamic Topic Model (DTM) to track topic evolution over time, and (2) a Text-Image Temporal Alignment Network (TITAN) to measure cross-modal consistency between narrative and visual stimuli. Experimental results show the effectiveness of the proposed approaches in NCD detection, with TITAN achieving superior performance across three corpora: ADReSS (F1=0.8889), ADReSSo (F1=0.8504), and CU-MARVEL-RABBIT (F1=0.7238). Feature contribution analysis reveals that macrostructural features (e.g., topic variability, topic change rate, and topic consistency) constitute the most significant contributors to the model’s decision pathways, outperforming the investigated microstructural features. These findings underscore the value of macrostructural analysis for understanding linguistic-cognitive interactions associated with NCDs.
@inproceedings{li2025detecting,url={https://doi.org/10.1109/JSTSP.2025.3622049},title={Detecting Neurocognitive Disorders through Analyses of Topic Evolution and Cross-modal Consistency in Visual-Stimulated Narratives},author={Li*, Jinchao and Wang*, Yuejiao and Li*, Junan and Kang*, Jiawen and Zheng, Bo and Wong, Simon and Mak, Brian and Fung, Helene and Woo, Jean and Mak, Man-Wai and Kwok, Timothy and Mok, Vincent and Gong, Xianmin and Wu, Xixin and Liu, Xunying and Wong, Patrick and Meng, Helen},booktitle={JSTSP},year={2025},organization={IEEE}}
Generate, Align and Predict (GAP): Detecting Neurocognitive Disorders via Cross-modal Consistency in Narratives
Junan
Li*, Jinchao
Li*, Simon
Wong, Xixin
Wu, Helen
Meng
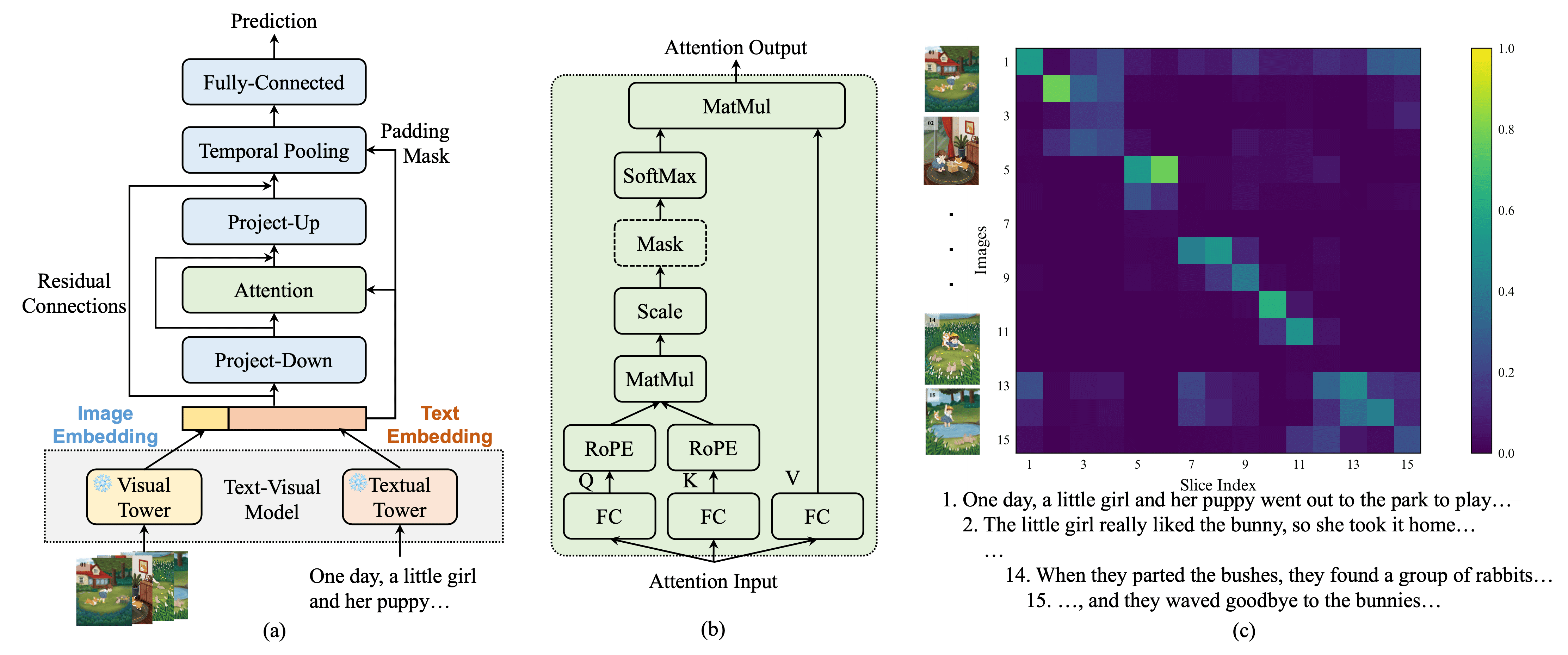
The early detection of neurocognitive disorders (NCDs), such as Alzheimer’s disease, remains a critical global health challenge due to the limitations of conventional diagnostic tools with high costs and limited accessibility. Visual-stimulated narrative (VSN)-based approach offers a promising alternative by capturing narrative patterns related to holistic cognitive domains. While prior work has focused on unimodal microstructural features (e.g., pauses, lexical diversity), macrostructural impairments—such as disrupted coherence and cross-modal inconsistency between narratives and visual stimuli—remain understudied despite their clinical importance. To address this, we propose GAP (Generate, Align, and Predict), a novel multimodal framework leveraging advances in Multimodal Large Language Models (MLLMs), Dynamic Programming (DP), and Vision-Language Model (VLM) to evaluate dynamic semantic consistency in VSNs. Evaluated on the Cantonese CU-MARVEL-RABBIT dataset, GAP achieved state-of-the-art performance (F1=0.65, AUC=0.75), outperforming traditional acoustic, linguistic, and pattern-matching baselines. In addition, we conduct an in-depth analysis that reveals key factors that provide insights into cognitive assessment using VSNs.
@inproceedings{li2025generate,url={https://dl.acm.org/doi/10.1145/3728424.3760767},title={Generate, Align and Predict (GAP): Detecting Neurocognitive Disorders via Cross-modal Consistency in Narratives},author={Li*, Junan and Li*, Jinchao and Wong, Simon and Wu, Xixin and Meng, Helen},booktitle={ACM-MM},year={2025},organization={ACM}}
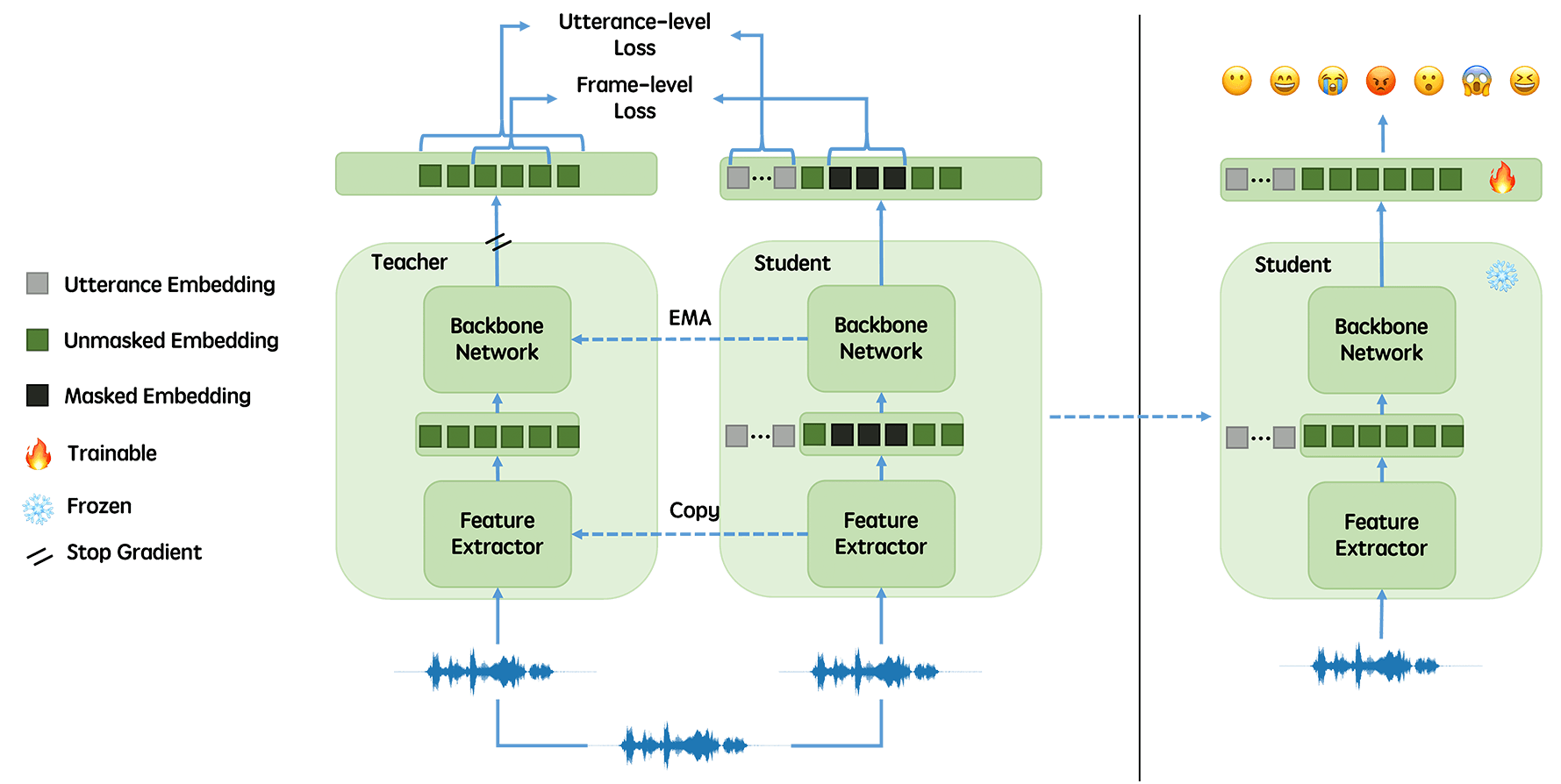
emotion2vec: Self-Supervised Pre-Training for Speech Emotion Representation
We propose emotion2vec, a universal speech emotion representation model.
emotion2vec is pre-trained on open-source unlabeled emotion data through self-supervised online distillation, combining utterance-level loss and frame-level loss during pre-training.
emotion2vec outperforms state-of-the-art pre-trained universal models and emotion specialist models by only training linear layers for the speech emotion recognition task on the mainstream IEMOCAP dataset.
In addition, emotion2vec shows consistent improvements among 10 different languages of speech emotion recognition datasets.
emotion2vec also shows excellent results on other emotion tasks, such as song emotion recognition, emotion prediction in conversation, and sentiment analysis.
Comparison experiments, ablation experiments, and visualization comprehensively demonstrate the universal capability of the proposed emotion2vec.
To the best of our knowledge, emotion2vec is the first universal representation model in various emotion-related tasks, filling a gap in the field.
@inproceedings{ma2023emotion2vec,url={https://arxiv.org/abs/2312.15185},title={emotion2vec: Self-Supervised Pre-Training for Speech Emotion Representation},author={Ma, Ziyang and Zheng, Zhisheng and Ye, Jiaxin and Li, Jinchao and Gao, Zhifu and Zhang, Shiliang and Chen, Xie},booktitle={ACL},year={2024},organization={ACL}}
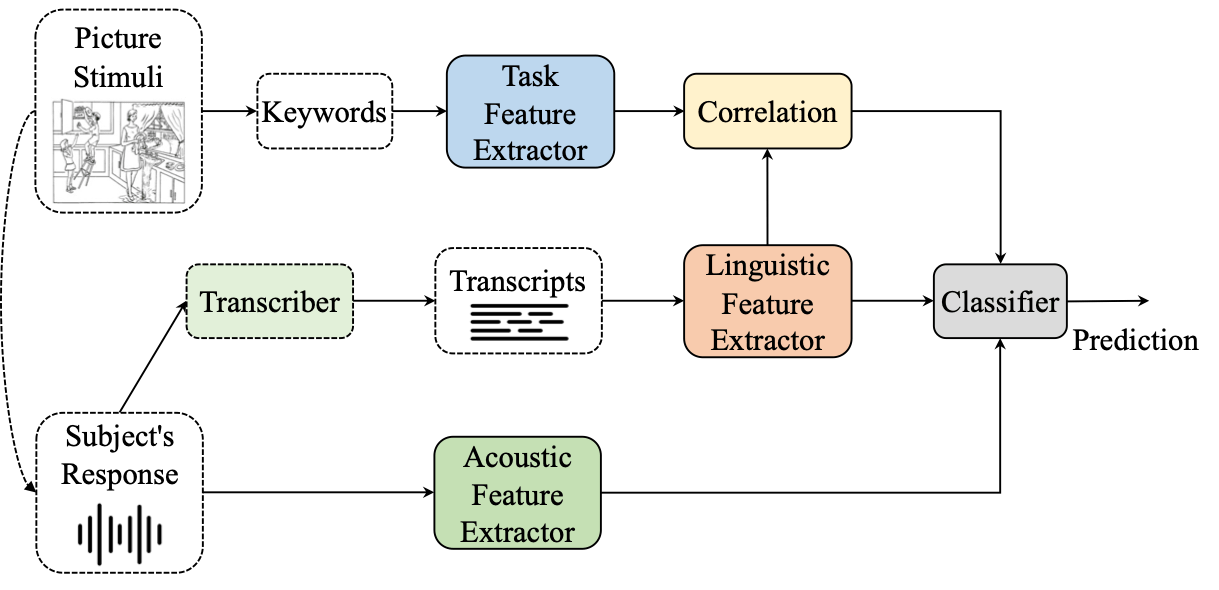
Leveraging Pretrained Representations With Task-Related Keywords for Alzheimer’s Disease Detection
Jinchao
Li, Kaitao
Song, Junan
Li, Bo
Zheng, Dongsheng
Li, Xixin
Wu, Xunying
Liu, Helen
Meng
With the global population aging rapidly, Alzheimer’s disease (AD) is particularly prominent in older adults, which has an insidious onset and leads to a gradual, irreversible deterioration in cognitive domains (memory, communication, etc.). Speech-based AD detection opens up the possibility of widespread screening and timely disease intervention. Recent advances in pre-trained models motivate AD detection modeling to shift from low-level features to high-level representations. This paper presents several efficient methods to extract better AD-related cues from high-level acoustic and linguistic features. Based on these features, the paper also proposes a novel task-oriented approach by modeling the relationship between the participants’ description and the cognitive task. Experiments are carried out on the ADReSS dataset in a binary classification setup, and models are evaluated on the unseen test set. Results and comparison with recent literature demonstrate the efficiency and superior performance of proposed acoustic, linguistic and task-oriented methods. The findings also show the importance of semantic and syntactic information, and feasibility of automation and generalization with the promising audio-only and task-oriented methods for the AD detection task.
@inproceedings{li2023leveraging,url={https://ieeexplore.ieee.org/document/10096205},title={Leveraging Pretrained Representations With Task-Related Keywords for Alzheimer’s Disease Detection},author={Li, Jinchao and Song, Kaitao and Li, Junan and Zheng, Bo and Li, Dongsheng and Wu, Xixin and Liu, Xunying and Meng, Helen},booktitle={ICASSP},year={2023},organization={IEEE}}
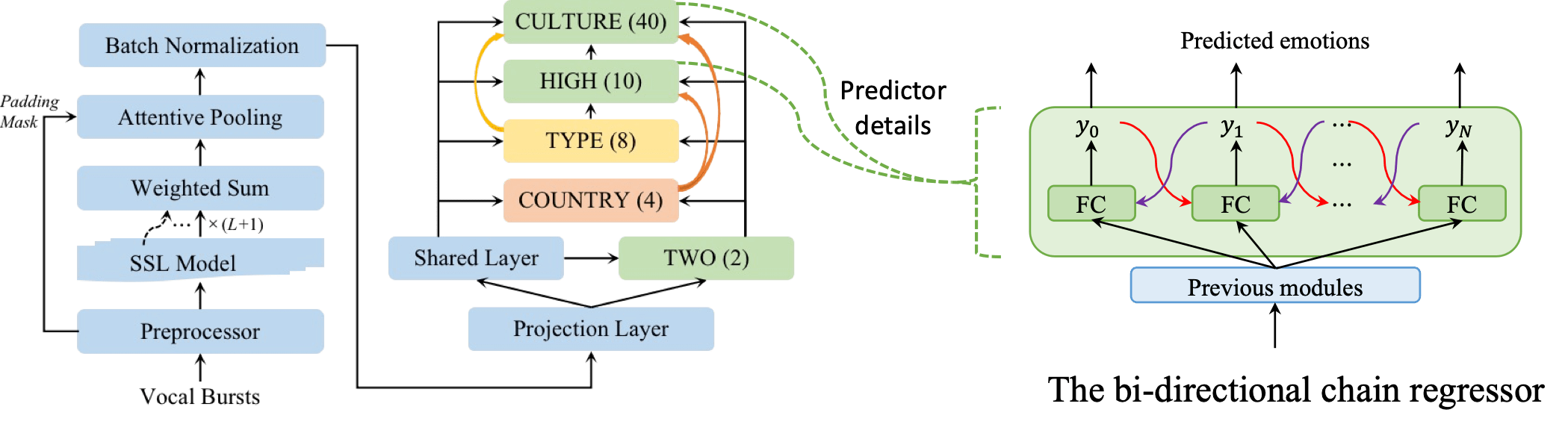
A Hierarchical Regression Chain Framework for Affective Vocal Burst Recognition
As a common way of emotion signaling via non-linguistic vocalizations, vocal burst (VB) plays an important role in daily social interaction. Understanding and modeling human vocal bursts are indispensable for developing robust and general artificial intelligence. Exploring computational approaches for understanding vocal bursts is attracting increasing research attention. In this work, we propose a hierarchical framework, based on chain regression models, for affective recognition from VBs, that explicitly considers multiple relationships: (i) between emotional states and diverse cultures; (ii) between low-dimensional (arousal & valence) and high-dimensional (10 emotion classes) emotion spaces; and (iii) between various emotion classes within the high-dimensional space. To address the challenge of data sparsity, we also use self-supervised learning (SSL) representations with layer-wise and temporal aggregation modules. The proposed systems participated in the ACII Affective Vocal Burst (A-VB) Challenge 2022 and ranked first in the "TWO” and "CULTURE” tasks. Experimental results based on the ACII Challenge 2022 dataset demonstrate the superior performance of the proposed system and the effectiveness of considering multiple relationships using hierarchical regression chain models.
@inproceedings{li2023hierarchical,url={https://ieeexplore.ieee.org/document/10096395/},title={A Hierarchical Regression Chain Framework for Affective Vocal Burst Recognition},author={Li, Jinchao and Wu, Xixin and Song, Kaitao and Li, Dongsheng and Liu, Xunying and Meng, Helen},booktitle={ICASSP},year={2023},organization={IEEE}}
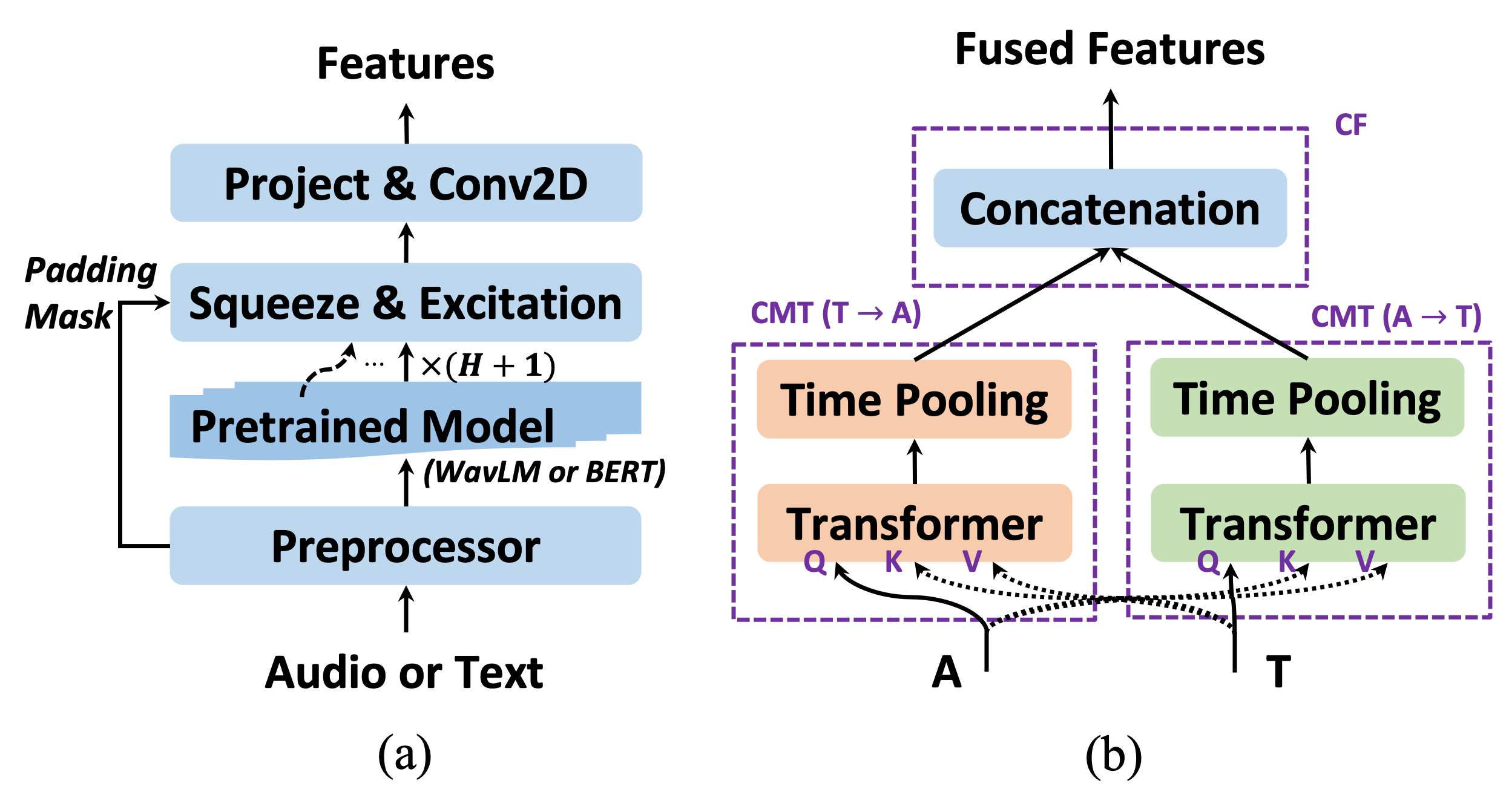
Context-Aware Multimodal Fusion for Emotion Recognition
Jinchao
Li, Shuai
Wang, Yang
Chao, Xunying
Liu, Helen
Meng
Automatic emotion recognition (AER) is an inherently complex multimodal task that aims to automatically determine the emotional state of a given expression. Recent works have witnessed the benefits of upstream pretrained models in both audio and textual modalities for the AER task. However, efforts are still needed to effectively integrate features across multiple modalities, devoting due considerations to granularity mismatch and asynchrony in time steps. In this work, we first validate the effectiveness of the upstream models in a unimodal setup and empirically find that partial fine-tuning of the pretrained model in the feature space can significantly boost performance. Moreover, we take the context of the current sentence to model a more accurate emotional state. Based on the unimodal setups, we further propose several multimodal fusion methods to combine high-level features from the audio and text modalities. Experiments are carried out on the IEMOCAP dataset in a 4-category classification problem and compared with state-of-the-art methods in recent literature. Results show that the proposed models gave a superior performance of up to 84.45% and 80.36% weighted accuracy scores respectively in Session 5 and 5-fold cross-validation settings.
@inproceedings{li2022context,url={https://www.isca-speech.org/archive/interspeech_2022/li22v_interspeech.html},title={Context-Aware Multimodal Fusion for Emotion Recognition},author={Li, Jinchao and Wang, Shuai and Chao, Yang and Liu, Xunying and Meng, Helen},booktitle={INTERSPEECH},year={2022},organization={IEEE}}
A Comparative Study of Acoustic and Linguistic Features Classification for Alzheimer’s Disease Detection
Jinchao
Li, Jianwei
Yu, Zi
Ye, Simon
Wong, Manwai
Mak, Brian
Mak, Xunying
Liu, Helen
Meng
With the global population ageing rapidly, Alzheimer’s Disease (AD) is particularly prominent in older adults, which has an insidious onset followed by gradual, irreversible deterioration in cognitive domains (memory, communication, etc). Thus the detection of Alzheimer’s Disease is crucial for timely intervention to slow down disease progression. This paper presents a comparative study of different acoustic and linguistic features for the AD detection using various classifiers. Experimental results on ADReSS dataset reflect that the proposed models using ComParE, X-vector, Linguistics, TFIDF and BERT features are able to detect AD with high accuracy and sensitivity, and are comparable with the state-of-the-art results reported. While most previous work used manual transcripts, our results also indicate that similar or even better performance could be obtained using automatically recognized transcripts over manually collected ones. This work achieves accuracy scores at 0.67 for acoustic features and 0.88 for linguistic features on either manual or ASR transcripts on the ADReSS Challenge test set.
@inproceedings{li2021comparative,url={https://ieeexplore.ieee.org/document/9414147},title={A Comparative Study of Acoustic and Linguistic Features Classification for Alzheimer's Disease Detection},author={Li, Jinchao and Yu, Jianwei and Ye, Zi and Wong, Simon and Mak, Manwai and Mak, Brian and Liu, Xunying and Meng, Helen},booktitle={ICASSP},year={2021},organization={IEEE}}
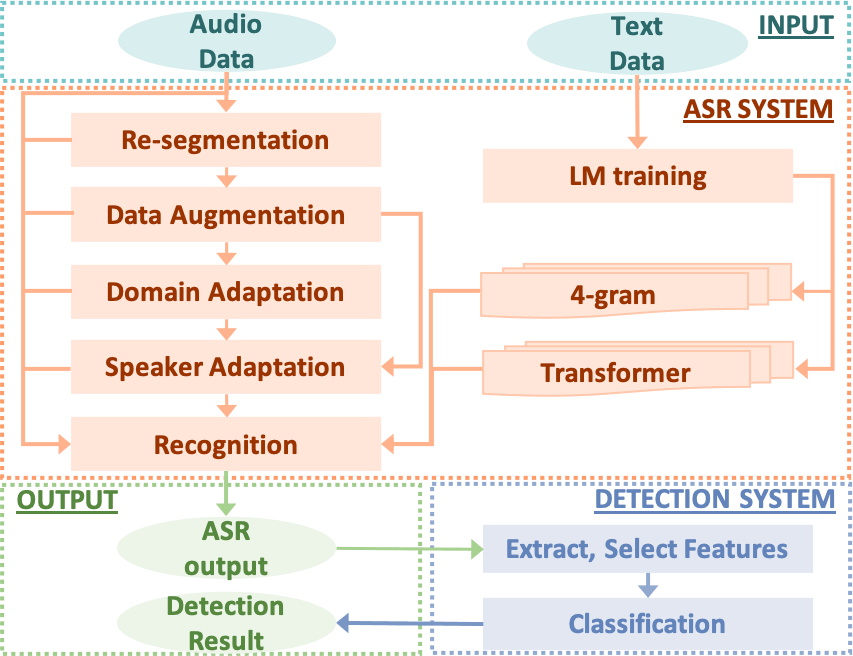
Development of the CUHK Elderly Speech Recognition System for Neurocognitive Disorder Detection Using the DementiaBank Corpus
Zi
Ye, Shoukang
Hu, Jinchao
Li, Xurong
Xie, Mengzhe
Geng, Jianwei
Yu,
4 more authors, Helen
Meng
Early diagnosis of Neurocognitive Disorder (NCD) is crucial in facilitating preventive care and timely treatment to delay further progression. This paper presents the development of a state-of-the-art automatic speech recognition (ASR) system built on the Dementia-Bank Pitt corpus for automatic NCD detection. Speed perturbation based audio data augmentation expanded the limited elderly speech data by four times. Large quantities of out-of-domain, non-aged adult speech were exploited by cross-domain adapting a 1000-hour LibriSpeech corpus trained LF-MMI factored TDNN system to DementiaBank. The variability among elderly speakers was modeled using i-Vector and learning hidden unit contributions (LHUC) based speaker adaptive training. Robust Bayesian estimation of TDNN systems and LHUC transforms were used in both cross-domain and speaker adaptation. A Transformer language model was also built to improve the final system performance. A word error rate (WER) reduction of 11.72% absolute (26.11% relative) was obtained over the baseline i-Vector adapted LF-MMI TDNN system on the evaluation data of 48 elderly speakers. The best NCD detection accuracy of 88%, comparable to that using the ground truth speech transcripts, was obtained using the textual features extracted from the final ASR system outputs.
@inproceedings{ye2021development,url={https://ieeexplore.ieee.org/document/9413634},title={Development of the CUHK Elderly Speech Recognition System for Neurocognitive Disorder Detection Using the DementiaBank Corpus},author={Ye, Zi and Hu, Shoukang and Li, Jinchao and Xie, Xurong and Geng, Mengzhe and Yu, Jianwei and Xu, Junhao and Xue, Boyang and Liu, Shansong and Liu, Xunying and Meng, Helen},booktitle={ICASSP},year={2021},organization={IEEE}}

 Detecting Neurocognitive Disorders through Analyses of Topic Evolution and Cross-modal Consistency in Visual-Stimulated NarrativesIn JSTSP, 2025
Detecting Neurocognitive Disorders through Analyses of Topic Evolution and Cross-modal Consistency in Visual-Stimulated NarrativesIn JSTSP, 2025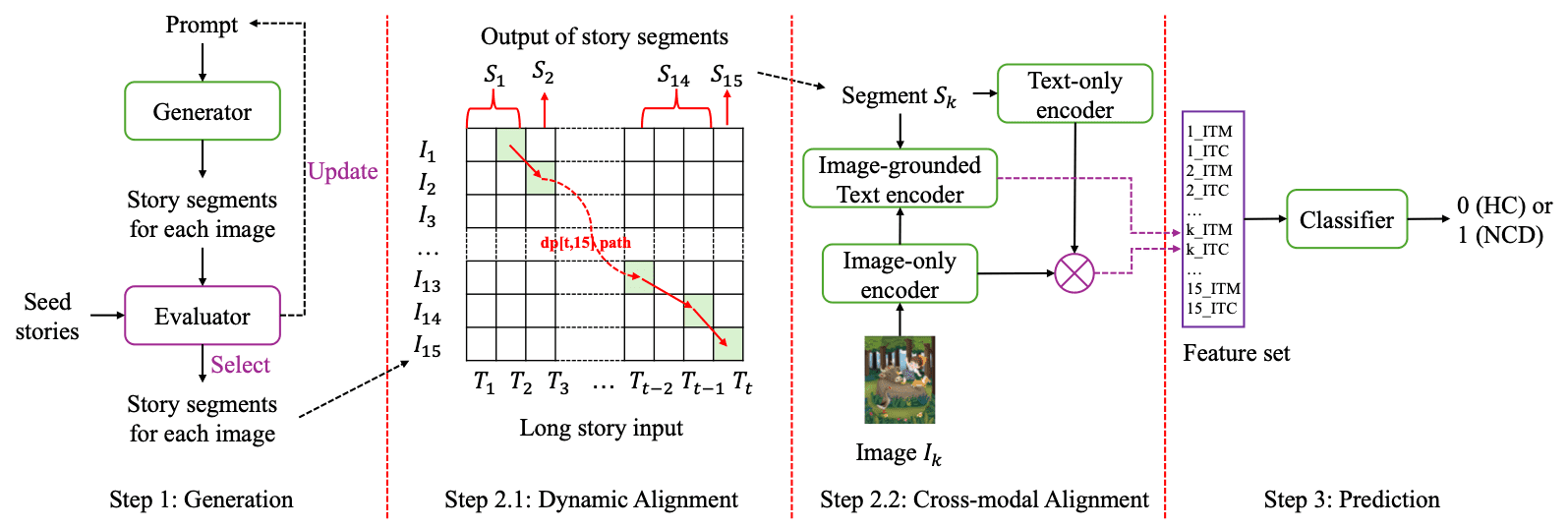 Generate, Align and Predict (GAP): Detecting Neurocognitive Disorders via Cross-modal Consistency in NarrativesIn ACM-MM, 2025
Generate, Align and Predict (GAP): Detecting Neurocognitive Disorders via Cross-modal Consistency in NarrativesIn ACM-MM, 2025