Thinking with Visual Primitives (转)
作者:PaperAgent
链接:https://zhuanlan.zhihu.com/p/2033494636023559146
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
上周DeepSeek V4发布了,但遗憾的还是没有多模态,今天(老规矩,节假日发布)DeepSeek把这块补上了,开源了最新的多模态技术&Paper:Thinking with Visual Primitives(以视觉原语思考)

DeepSeek&北京大学&清华大学提出”视觉基元推理”框架,将边界框与坐标点提升为”最小思考单元”,解决MLLM在复杂空间推理中的Reference Gap(指代鸿沟)问题。基于DeepSeek-V4-Flash构建的模型,在仅使用约90个KV Cache视觉token的情况下,性能比肩GPT-5.4、Claude-Sonnet-4.6与Gemini-3-Flash。Skills驱动推理新范式,清华&北大:Token立省59%

一、从感知鸿沟到指代鸿沟:问题重新定义
当前多模态大语言模型(MLLM)的Chain-of-Thought(CoT)推理几乎完全发生在语言空间。即便前沿模型通过高分辨率裁剪、动态分块等策略解决了”看不清”的Perception Gap(感知鸿沟),它们在面对密集计数、拓扑导航、多步空间推演时,仍然频繁出现逻辑崩塌(logical collapse)。
DeepSeek团队指出,这背后是一个更本质的瓶颈——Reference Gap(指代鸿沟):
自然语言天生是模糊、连续的,而视觉空间是精确、离散的。当模型用语言描述”左边第二个红色的物体”时,它实际上已经丢失了精确的空间锚点,导致推理链条与图像实体脱节,最终引发级联幻觉。
人类是如何解决这个问题的?我们在数一堆密集物体或走迷宫时,会本能地用手指指向目标,将抽象的语义概念锚定到具体的物理坐标上,大幅降低工作记忆负担。
受此启发,论文提出Thinking with Visual Primitives(基于视觉基元的思考):将边界框(bounding boxes)和点(points)提升为与语言token同级的”最小思考单元”,直接交错插入模型的推理轨迹中。模型不再是”说完再指”,而是边指边想(point while it reasons)。
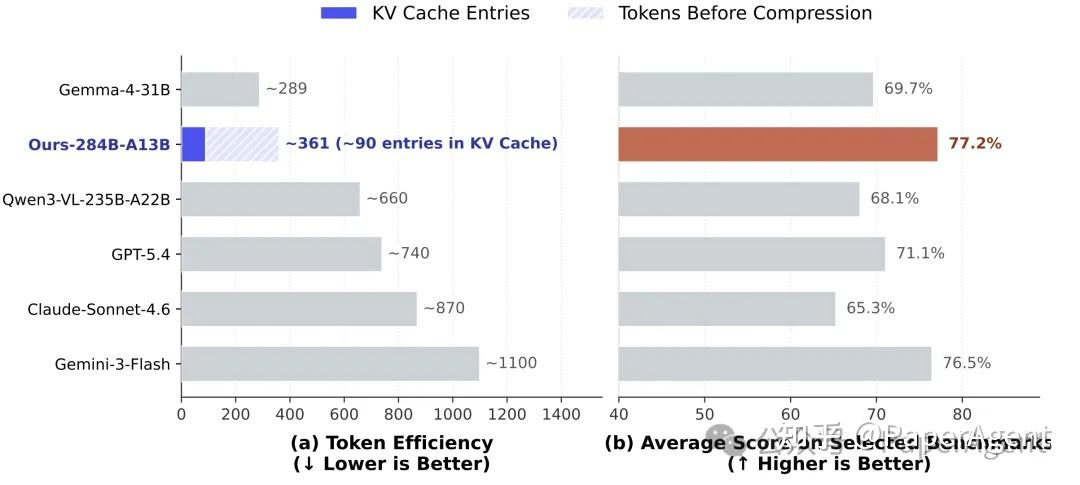
Figure 1对比了各模型在800×800分辨率下的KV Cache Entries与7项基准平均分
Figure 1揭示了这一范式的惊人效率:对于800×800的输入,该模型在KV Cache中仅保留约90个视觉条目(总token约361),远低于GPT-5.4(~740)、Claude-Sonnet-4.6(~870)和Gemini-3-Flash(~1100),同时在计数与空间推理任务上取得77.2%的平均分,超越所有对比模型。
二、架构与训练 pipeline:效率与专项能力的平衡
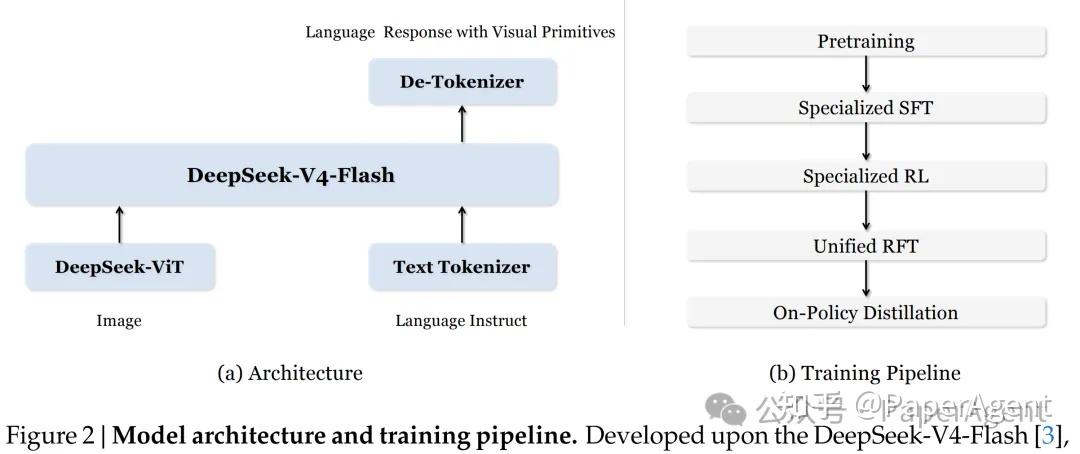
2.1 架构设计
模型采用类LLaVA的标准架构,以DeepSeek-V4-Flash(284B总参数,13B激活参数的MoE模型)为语言骨干,视觉编码器采用自研的DeepSeek-ViT,支持任意分辨率输入。
极致压缩是架构的核心:
- 14×14 Patch Embedding:将图像切分为基础patch;
- 3×3空间压缩:每9个相邻patch在通道维度压缩为1个token;
- *Compressed Sparse Attention (CSA)**:在LLM的KV Cache层进一步压缩视觉token。
以756×756图像为例:原始571,536像素 → ViT处理为2,916个patch token → 3×3压缩后324个token送入LLM → CSA机制最终仅保留81个视觉KV条目。从原始像素到KV Cache,整体压缩比高达7,056:1。
2.2 五阶段后训练流程
论文设计了一套”先训专家,再合并”的范式:
- Pretraining:在数万亿多模态token上预训练,赋予模型输出视觉基元的基础能力;
- Specialized SFT:分别针对Box(FTwG)和Point(FTwP)构建冷启动数据,独立微调,避免模态冲突;
- Specialized RL:对两个专家模型分别应用GRPO强化学习,使用格式、质量、准确率三重Reward Model;
- Unified RFT:用两位专家模型生成拒绝采样数据,统一训练一个融合模型;
- On-Policy Distillation:通过反向KL散度,将专家模型的输出分布蒸馏到统一模型,弥合性能差距。
三、冷启动数据构造:四大推理场景的精细化设计
为了让模型学会”用基元思考”,团队没有依赖简单的指令微调,而是为四类任务构建了带显式视觉锚定的思维链冷启动数据。
3.1 计数(Counting)
MLLM在密集场景中计数失败,本质是无法建立”语言数字↔视觉实体”的一一对应。
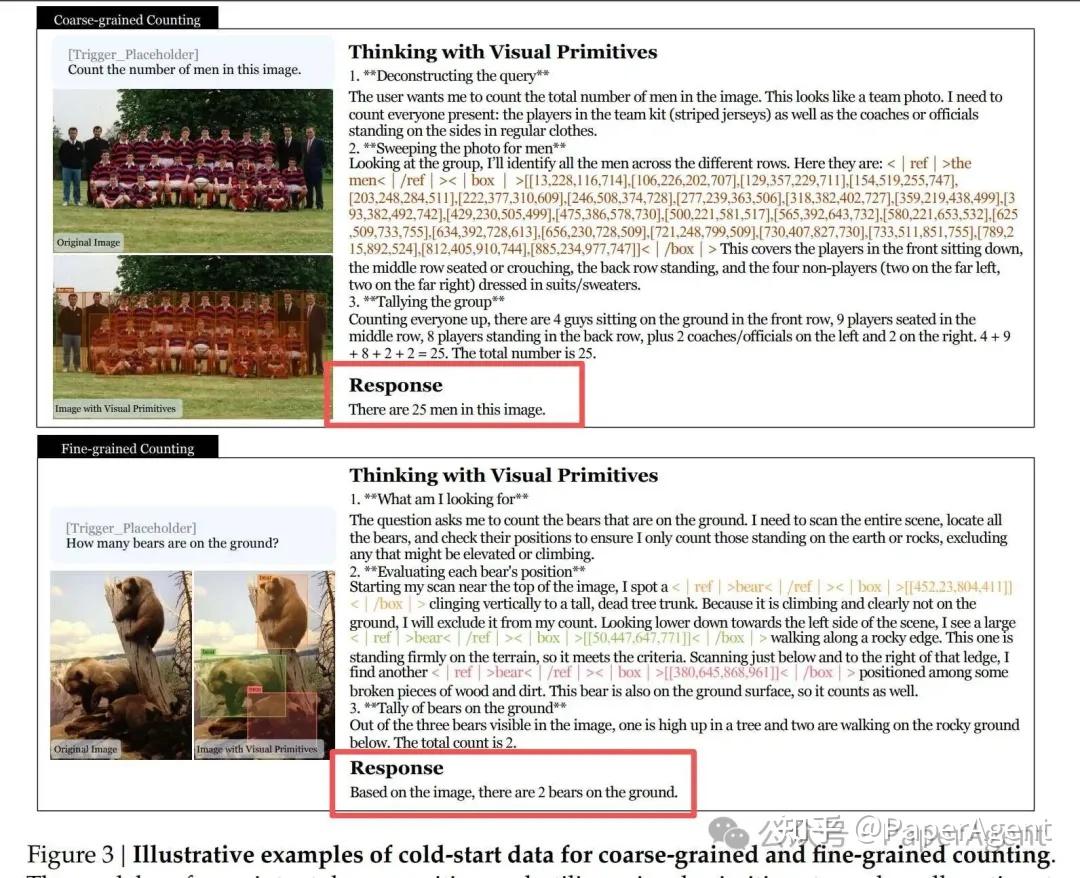
包含足球队照片与熊群照片的两个完整推理案例
- 粗粒度计数:模型先进行意图分析,再批量 grounding(同时框出所有候选对象),最后统计求和。Figure 3展示了对团队照片的人数统计,模型一次性框出25个人,再分排验证。
- 细粒度计数:基于GQA场景图构造属性约束问题(如”地面上的熊有几只”),模型需逐一枚举验证,排除不符合属性的负样本。
3.2 空间推理与通用VQA(Spatial Reasoning & General VQA)
利用GQA和CLEVR构造数据。在CLEVR合成场景中,模型需要执行多跳逻辑推理(如”与灰色金属球同尺寸的紫色橡胶物体是否存在”)。每个推理步骤都必须通过<|ref|>...<|/ref|><|box|>...<|/box|>将提及的物体锚定到图像坐标,避免语义漂移。

展示CLEVR场景中多属性验证的完整思维链
3.3 迷宫导航(Maze Navigation)
这是检验拓扑推理能力的极端场景。纯语言CoT难以描述不规则路径的连通性。
团队使用DFS、Prim、Kruskal算法生成矩形、圆形、六边形三种迷宫拓扑,并构造不可解迷宫(在路径中段故意设墙)。模型的思维链以<|point|>[[x,y]]<|/point|>记录每一步探索坐标,形成类似人类”试错-回溯”的DFS轨迹。
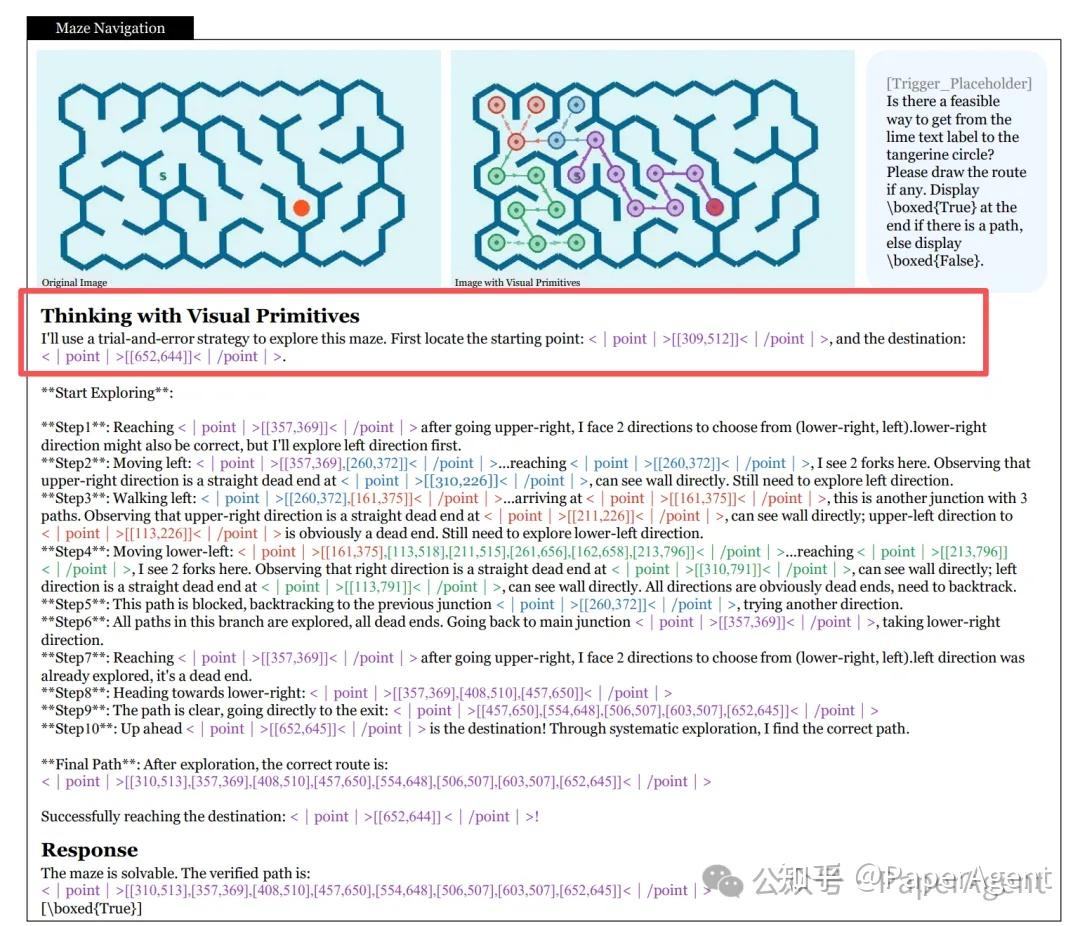
展示六边形迷宫中从起点到终点的完整探索与回溯过程
3.4 路径追踪(Path Tracing)
在缠绕的贝塞尔曲线中,模型需要追踪指定线条找到终点。难点在于交叉点消歧:当两条线相交时,模型必须依据局部几何连续性判断走向,而非依赖颜色捷径。思维链以自适应密度的坐标序列记录路径——直线段稀疏采样,弯曲/交叉处密集采样。

展示从皇冠图标出发追踪洋红色曲线至终点的过程
四、Reward Model设计:让强化学习”看懂”视觉推理
在Specialized RL阶段,论文为不同任务设计了精细的Accuracy RM:
| 任务 | Reward Model核心逻辑 |
|---|---|
| 计数 | 基于相对误差的指数衰减奖励:$R = \alpha \cdot \exp(-\beta \cdot \frac{ |
| 空间推理/VQA | LLM-based GRM,分别对思维链和最终回答评分后取平均 |
| 迷宫导航 | 四维加权:因果探索进度(截断于首次撞墙)、探索完整度(不可解迷宫)、撞墙惩罚、最终路径有效性 |
| 路径追踪 | 双向轨迹对齐(预测点→真值线 / 真值点→预测线)、端点精度、轨迹连续性惩罚(禁止跳点) |
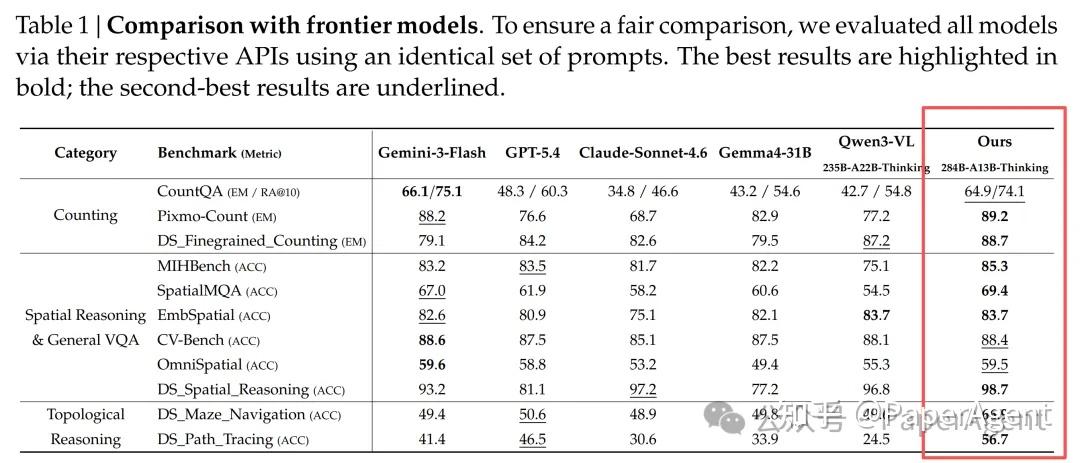
Table 1的结果极具说服力:
- 计数:Pixmo-Count达到89.2%,超越所有对手;CountQA上RA@10为74.1%,仅次于Gemini-3-Flash;
- 空间推理:DS_Spatial_Reasoning达到98.7%,显著领先Claude的97.2%和Qwen3-VL的96.8%;
- 拓扑推理:这是所有前沿模型的盲区。DS_Maze_Navigation 66.9%(次高仅50.6%),DS_Path_Tracing 56.7%(次高仅46.5%),形成断层式领先。
五、定性分析:视觉基元如何重塑推理体验
论文通过大量案例展示,视觉基元不仅是内部推理工具,更外化为可解释的”注意力轨迹”。
5.1 边界框作为基元
模型展现出强大的涌现协同能力:
- 世界知识融合:看到金门大桥照片,模型框出大桥主体,关联到旧金山,进而回答”附近有NBA球队吗”(金州勇士);

- 反事实推理:在”天平哪边更重”问题中,模型框出左右物体及托盘,通过视觉证据(倾斜角度)推翻外观直觉;

- 可操作建议:在”如何做拿铁”问题中,模型框出咖啡机、蒸汽棒、奶壶、咖啡豆、杯子,给出带空间坐标的操作步骤。

5.2 点作为基元
在迷宫和路径追踪中,模型输出的点序列构成了可视化的推理路径。人类可以沿着这些坐标还原模型的”心路历程”:何时尝试分支、何时发现死胡同、何时回溯。这种可解释性是纯语言CoT无法提供的。
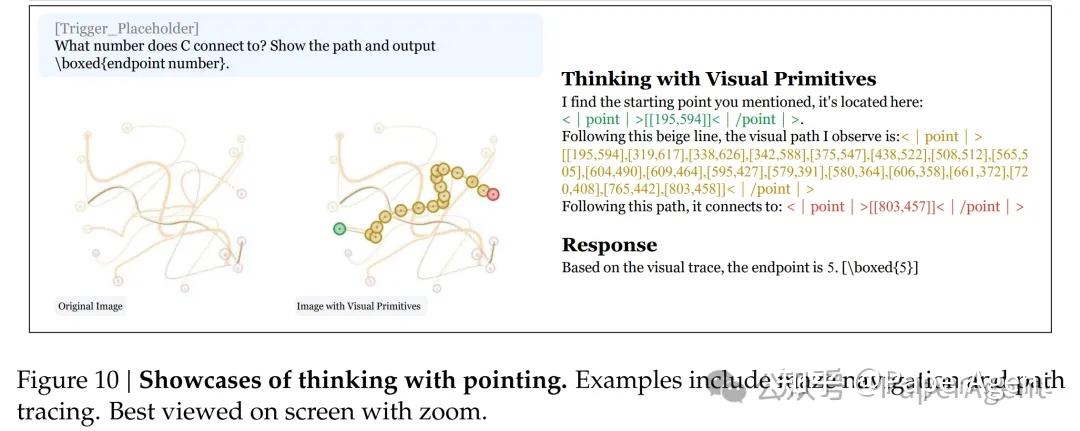
圆形迷宫导航与多曲线追踪
https://github.com/deepseek-ai/Thinking-with-Visual-Primitives/blob/main/Thinking_with_Visual_Primitives.pdf